k-means clustering 学习笔记
其实这算法巨简单。。。。让我想到了均分纸牌(noip200?
还是大致说一下:
对于有 features 但是 **没有 **labels 的数据,没办法用监督学习,但是可以使用非监督学习的聚类算法。
所谓聚类,简单理解,就是把相似的分成一组。。。
k-means就是一个常见的聚类算法。。。
k代表可以把数据分成k组。
举一个平面上二维点的例子,算法步骤如下:
1. 随机k个点当做k个点作为k组的中心。
2. 根据现在的k个中心,将数据集中的点,按照【距离哪个中心最近就属于哪个中心】的原则,分组。
3. 在每一个组内求点的二维平均数,作为新的中心。**如果存在一个组的数据中心改变,那么返回2,否则结束**。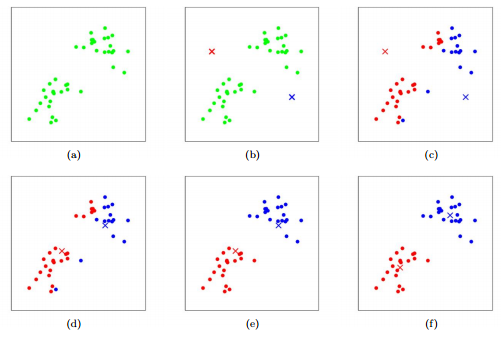
可以很容易推广到高维度,就只是求平均数和算距离的时候有区别。
一般化的流程:

然后该算法是Expectation Maximization的一个特例
该算法和KNN算法没有半毛钱关系。。。
参考资料: