TensorFlow Architecture 学习笔记(一)
这篇文章不会涉及tensorflow的具体使用,而是专注于介绍tensorflow的架构,目的是让开发者能够对tensorflow现有框架进行自定义的扩展。
tensorflow被设计用来处理大规模分布式训练,但是也足够灵活去处理新的machine learning模型或是系统层面的优化。
Overview
tensorflow的结构图如下:
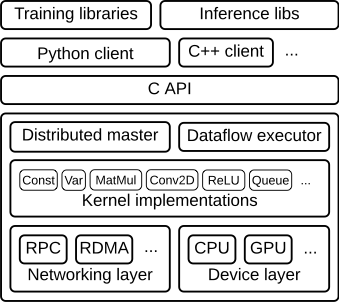
从下往上大致上抽象程度越来越高。
其中C API那一层将tensorflow底层的runtime core 封装成不同语言(python,cpp,etc)的用户层代码,并提供相应的接口
这篇文章主要侧重如下layer:
* **Client**:
* 将计算定义为数据流图.
* 使用 **[session](https://www.github.com/tensorflow/tensorflow/blob/r1.2/tensorflow/python/client/session.py)(**会话)启动图 的执行
* **Distributed Master**
* 通过Session.run()中参数的定义,修改图中特定的子图
* 将子图分成多个pieces,使之运行在不同的进程和设备中)
* 将得到的pieces分发到 worker services上
* 由worker services 启动graph pieces
* **Worker Services** (one for each task)
* Schedule the execution of graph operations using kernel implementations appropriate to the available hardware (CPUs, GPUs, etc).
* 使用kernel中对于特定硬件设备(cpu,gpu,etc)合适的实现去安全图中操作的执行。
* 从其他worker service 处发送或接收运算结果
* **Kernel Implementations**
* 完成各个操作的计算
client,master,worker的关系如下

"/job:worker/task:0" 和"/job:ps/task:0"都是运行在worker service上的tasks
其中ps是“parameter server”的缩写,也就是参数服务器。
PS负责模型参数的存储和更新,其他task在优化模型的参数的时候,会将更新传给ps
ps的命名是按照使用来定义的,也就是哪个(些)worker services 用来承担了 parmmeter server 的task,那么其就被称之为ps
需要注意的是maaster和worker service是分布式tensorflow框架才有的概念。
Client
client就是和用户直接接触的那一层。用户通过Client program完成图的定义。
clinet program 中的operation可以是自己定义的,也可以直接调用现成的一些库
之后client 创建 一个session,session将刚刚定义好的图传到master节点,当client想要计算图中某个节点时,就会触发对master节点的调用从而开始计算。
下面为运算 S+=w*x+b 所建的图:

Distributed master
* 对graph进行修剪以获得 完成client要求的运算所需要的子图。
* 划分graph,得到为每一个设备准备的graph pieces
* 将这些graph pieces 缓存起来,以期在接下来的步骤中复用。
由于master节点可以看到计算的全局步骤,因此在master节点处可以进行一些常见的编译优化。
比如Common_subexpression_elimination 和Constant folding
所谓common_subexpression_elimination,指的就是对于同一个表达式的重复运算,我们在第一次运算后将其存起来,下次直接调用,以空间换时间
比如下面这个例子
1a = b * c + g;
2d = b * c * e;
3#it may be worth transforming the code to:
1tmp = b * c;
2a = tmp + g;
3d = tmp * e;
核心思想就是添加记忆化,尽力不做重复计算
而所谓constant folding,其实就是在编译期间,将可以化简的常数先计算出来。通常在编译的中间代码生成阶段完成。
在进行完这些优化后,master将优化过的子图的执行分配到不同的task上(此时只是设定分配方案)

下图是一个图的可能的划分(partition)

由于划分成了不同的task,在不同的卡上运行,因此出现了通信的问题。
因此在被划分的位置,添加recv和send节点来在不同的task之间传递信息,如下图:

然后master节点按照之前的分配,将graph pieces 传送给不同的task

Worker Service
* 处理来自master节点的请求
* 安排构成子图的运算的核心程序(kernels)
* 协调task之间的通信任务
简单说明下对于不同的设备,Send和Recv操作:
* cpu和gpu之间的通信使用_`cudaMemcpyAsync()` _API
* gpu之间的通信直接使用端到端的DMA,避免了经过cpu通信的昂贵代价。a
对于task之间的通信,tensorflow使用了多种协议,包括:
* gRPC over TCP.
* RDMA over Converged Ethernet.
除此之外,对于多个gpu之间的通信,我们也已经开始准备支持NVIDIA's NCCL library.

Kernel Implementations
runtime本身包含200+个标准运算,对于有些通过标准运算难以构成的图,用户可以注册额外的kernel来实现自定义的运算。
这个过程需要编写cpp代码实现。
其中 XLA Compiler 提出了一些实验性的解决方法,可以参考。
XLA是一个google专门为tensorflow设计的,用来加速线性代数运算的编译器。
关于XLA的内容,见________(我还没有写orz