多标签图像分类任务的评价方法-mean average precision(mAP) 以及top x的评价方法
参考资料:
wiki_Sensitivity and specificity
False Positives和False Negative等含义
mean average precision(MAP)在计算机视觉中是如何计算和应用的?
首先需要了解True(False) Positives (Negatives)的含义
True Positive (真正, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负 , FN)被模型预测为负的正样本;可以称作漏报率
在图像中,尤其是分类问题中应用AP,是一种评价ranking方式好不好的指标:
举例来说,我有一个两类分类问题,分别5个样本,如果这个分类器性能达到完美的话,ranking结果应该是+1,+1,+1,+1,+1,-1,-1,-1,-1,-1.
但是分类器预测的label,和实际的score肯定不会这么完美。按照从大到小来打分,我们可以计算两个指标:precision和recall。比如分类器认为打分由高到低选择了前四个,实际上这里面只有两个是正样本。此时的recall就是2(你能包住的正样本数)/5(总共的正样本数)=0.4,precision是2(你选对了的)/4(总共选的)=0.5.
图像分类中,这个打分score可以由SVM得到:s=w^Tx+b就是每一个样本的分数。
从上面的例子可以看出,其实precision,recall都是选多少个样本k的函数,很容易想到,如果我总共有1000个样本,那么我就可以像这样计算1000对P-R,并且把他们画出来,这就是PR曲线:
这里有一个趋势,recall越高,precision越低。这是很合理的,因为假如说我把1000个全拿进来,那肯定正样本都包住了,recall=1,但是此时precision就很小了,因为我全部认为他们是正样本。recall=1时的precision的数值,等于正样本所占的比例。
所以AP,average precision,就是这个曲线下的面积,这里average,等于是对recall取平均。而mean average precision的mean,是对所有类别取平均(每一个类当做一次二分类任务)。现在的图像分类论文基本都是用mAP作为标准。
使用AP会比accuracy要合理。对于accuracy,如果有9个负样本和一个正样本,那么即使分类器什么都不做全部判定为负样本accuracy也有90%。但是对于AP,recall=1那个点precision会掉到0.1.曲线下面积就会反映出来。
precision 和 recall 的计算:
<img src="https://pic2.zhimg.com/50/v2-761706f5b1fe36873ba1bb20c7d1d447_hd.jpg" data-rawwidth="301" data-rawheight="541" class="content_image" width="301">
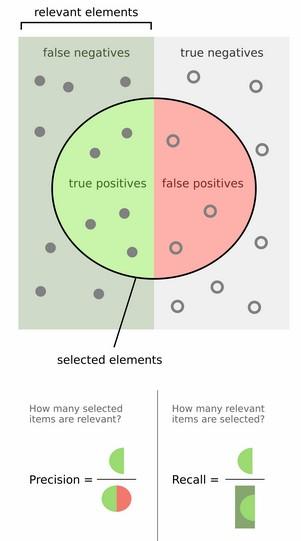
图中上部分,左边一整个矩形中(false negative和true positive)的数表示ground truth之中为1的(即为正确的)数据,右边一整个矩形中的数表示ground truth之中为0的数据。
精度precision的计算是用 检测正确的数据个数/总的检测个数。
召回率recall的计算是用 检测正确的数据个数/ground truth之中所有正数据个数。
- AP:average precision
假设我们有数据:
<img src="https://pic1.zhimg.com/50/v2-7189c118955fced185b5f1ebbd6996af_hd.jpg" data-rawwidth="242" data-rawheight="277" class="content_image" width="242">
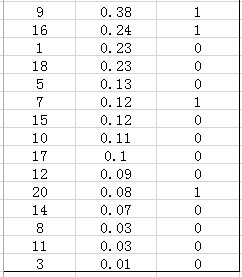
一共20个图像,20行,第一列是图像index, 第二列是检测confidence, 第三列是ground truth。根据confidence从大到小排列。
每检测一个图像时,无论是正例还是负例,计算当下的precision和recall。
假设检测样本中每N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, ..., M/M)(由于检测N'数量正样本时,precision有不同情况),对于每个recall值r,我们可以计算出对应(r' > r)的最大precision,然后对这些max precision取平均即得到最后的AP值。具体计算如图,top-N是指根据confidence降级排列后样本的排位号(eg. 1为confidence最大的图像9):
<img src="https://pic1.zhimg.com/50/v2-f1622970915d9868bb46620e820388e1_hd.jpg" data-rawwidth="690" data-rawheight="331" class="origin_image zh-lightbox-thumb" width="690" data-original="https://pic1.zhimg.com/v2-f1622970915d9868bb46620e820388e1_r.jpg">
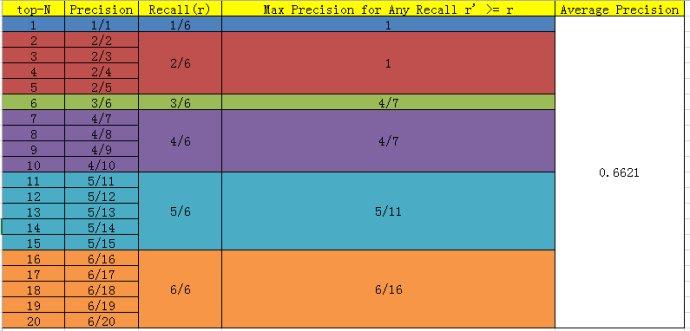
- mAP: mean average precision
多类的检测中,取每个类AP的平均值,即为mAP。
既然说到了分类任务的评价办法,顺便就把top x也提一句好了.通常是top1 ,top5
top1就是你预测的label取最后概率向量里面最大的那一个作为预测结果,你的预测结果中概率最大的那个类必须是正确类别才算预测正确。而top5就是最后概率向量最大的前五名中出现了正确概率即为预测正确。
** **