2019年2月24:完成了除了"Challenge"以外的全部练习和问题. 总共花费15个小时.#
2019年2月26:完成"Challenge 2"(应该是最简单的一个orz,只花了不到一个小时)#
Part 1: Physical Page Management#
操作系统必须时刻追踪哪些物理内存在使用,哪些物理内存没有在使用。
一个问题是,
Ex 1. In the file kern/pmap.c, you must implement code for the following functions (probably in the order given).
boot_alloc() mem_init() (only up to the call to check_page_free_list(1)) page_init() page_alloc() page_free()
check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes. You may find it helpful to add your own assert()s to verify that your assumptions are correct.
练习1要求写一个physical page allocator。我们先看第一个函数boot_alloc()
1 // This simple physical memory allocator is used only while JOS is setting
2 // up its virtual memory system. page_alloc() is the real allocator.
3 //
4 // If n>0, allocates enough pages of contiguous physical memory to hold 'n'
5 // bytes. Doesn't initialize the memory. Returns a kernel virtual address.
6 //
7 // If n==0, returns the address of the next free page without allocating
8 // anything.
9 //
10 // If we're out of memory, boot_alloc should panic.
11 // This function may ONLY be used during initialization,
12 // before the page_free_list list has been set up.
13 static void *
14 boot_alloc(uint32_t n)
15 {
16 static char *nextfree; // virtual address of next byte of free memory
17 char *result;
18
19 // Initialize nextfree if this is the first time.
20 // 'end' is a magic symbol automatically generated by the linker,
21 // which points to the end of the kernel's bss segment:
22 // the first virtual address that the linker did *not* assign
23 // to any kernel code or global variables.
24 if (!nextfree) {
25 extern char end[];
26 nextfree = ROUNDUP((char *) end, PGSIZE);
27 }
28
29 // Allocate a chunk large enough to hold 'n' bytes, then update
30 // nextfree. Make sure nextfree is kept aligned
31 // to a multiple of PGSIZE.
32 // ???
33 // how to allocate a memoty chunk?
34 // how to decide how many PA left?
35 // LAB 2: Your code here.
36
37 return NULL;
38 }
39
这个函数只有在JOS初始化虚拟内存之前会被调用一次。
通过查看 mem_init 函数可以知道,boot_alloc 是用来初始化页目录(page directory)
为什么我们需要一个单独的page allocator呢?原因是:
kernel启动时需要将物理地址映射到虚拟地址,而我们需要一个page table来记录这种映射关系。但是创建一个page table涉及到为page table所在的page分配空间…而为一个page分配空间需要在将物理地址映射到虚拟地址以后。。
解决办法是,使用一个单独的page allocator,在一个固定的位置allocate memory. 然后在这部分去做初始化的工作。
参考xv6-book:
There is a bootstrap problem: all of physical memory must be mapped in order for the allocator to initialize the free list, but creating a page table with those mappings involves allocating page-table pages. xv6 solves this problem by using a separate page allocator during entry, which allocates memory just after the end of the kernel’s data segment. This allocator does not support freeing and is limited by the 4 MB mapping in the entrypgdir, but that is sufficient to allocate the first kernel page table.
这个函数有两个难点,第一个是,如何才能"allocate memory"? 说到"allocate memory"总是想到malloc…但是现在我们什么都没有…
然而实际上很简单(虽然我卡了好一会。。。),我们只要计算出第一个虚拟地址就好了。根据注释, magic symbol ‘end’位于没有被任何kernel code或全局变量占用的虚拟地址的起始位置。
第二个是,如何确定何时空间不够? 我们观察函数i386_detect_memory
1 static void
2 i386_detect_memory(void)
3 {
4 size_t basemem, extmem, ext16mem, totalmem;
5
6 // Use CMOS calls to measure available base & extended memory.
7 // (CMOS calls return results in kilobytes.)
8 basemem = nvram_read(NVRAM_BASELO);
9 extmem = nvram_read(NVRAM_EXTLO);
10 ext16mem = nvram_read(NVRAM_EXT16LO) * 64;
11
12 // Calculate the number of physical pages available in both base
13 // and extended memory.
14 if (ext16mem)
15 totalmem = 16 * 1024 + ext16mem;
16 else if (extmem)
17 totalmem = 1 * 1024 + extmem;
18 else
19 totalmem = basemem;
20
21 npages = totalmem / (PGSIZE / 1024);
22 npages_basemem = basemem / (PGSIZE / 1024);
23
24 cprintf("Physical memory: %uK available, base = %uK, extended = %uK\n",
25 totalmem, basemem, totalmem - basemem);
26 }发现这个函数的作用是得到剩余的物理内存。其中basemem就是0-640k之间的memory,extmem是1M以后的memory.
npages是剩余物理内存的页数,每页的大小是PGSIZE。因此一共能分配的空间大小为(npages*PGSIZE)
而虚拟地址的base为KERNBASE(定义在inc/memlayout.h中),因此最大能访问的虚拟地址为KERNBASE+(npages*PGSIZE)
最后的实现为:
1 static void *
2 boot_alloc(uint32_t n)
3 {
4 static char *nextfree; // virtual address of next byte of free memory
5 char *result;
6
7 // Initialize nextfree if this is the first time.
8 // 'end' is a magic symbol automatically generated by the linker,
9 // which points to the end of the kernel's bss segment:
10 // the first virtual address that the linker did *not* assign
11 // to any kernel code or global variables.
12 // end 就是虚拟地址的初始位置
13 if (!nextfree) {
14 extern char end[];
15 nextfree = ROUNDUP((char *) end, PGSIZE);
16 cprintf("end:x nextfree:x\n",end,nextfree);
17 }
18
19 // Allocate a chunk large enough to hold 'n' bytes, then update
20 // nextfree. Make sure nextfree is kept aligned
21 // to a multiple of PGSIZE.
22 //
23 // LAB 2: Your code here.
24 cprintf("boot_alloc!\n");
25 if ( 0 == n) return nextfree;
26
27 nextfree = ROUNDUP((char *)(nextfree+n),PGSIZE);
28 //uint32_t x = (uint32_t)nextfree;
29 // cprintf("nextfree :x\n",x);
30 if ((uint32_t)nextfree>(KERNBASE+npages*PGSIZE))
31 {
32 panic("boot_alloc: there is no enough space\n");
33 }
34
35 return nextfree;
36 }接下来的部分就相对简单了。首先是mem_init,初始化PageInfo,由于是在page_init之前,不能使用page_alloc,因此这部分allocate也是由boot_alloc完成的。这也是唯二的由boot_alloc来分配内存的部分。代码如下:
1
2 pages = (struct PageInfo *)boot_alloc(sizeof(struct PageInfo)*npages);
3 memset(pages,0,sizeof(struct PageInfo)*npages);
4 cprintf("page_info_end_VA:x\n",pages+sizeof(struct PageInfo)*npages);接下来是page_init.这部分主要是判断哪些page是free的,哪些不是,参考注释,主要是[EXTPHYSMEM,…)这部分。 我们知道,对于EXTPHYSMEM之上的内存空间,首先kernel占用的空间,kernel之后是分配给kern_pgdir的空间,再然后是分配给PageInfo的空间。这之后的空间,应该都是可用的。因此代码如下:
1 void
2 page_init(void)
3 {
4 // The example code here marks all physical pages as free.
5 // However this is not truly the case. What memory is free?
6 // 1) Mark physical page 0 as in use.
7 // This way we preserve the real-mode IDT and BIOS structures
8 // in case we ever need them. (Currently we don't, but...)
9 // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
10 // is free.
11 // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
12 // never be allocated.
13 // 4) Then extended memory [EXTPHYSMEM, ...).
14 // Some of it is in use, some is free. Where is the kernel
15 // in physical memory? Which pages are already in use for
16 // page tables and other data structures?
17 //
18 //
19 // [EXTPHYSMEM,...)中,最开始是kernel,然后是分配给了page_dir,接着是npages个struct PageInfo.
20 // 这之后的空间应该都是free的
21 //
22 // Change the code to reflect this.
23 // NB: DO NOT actually touch the physical memory corresponding to
24 // free pages!
25 size_t i;
26 cprintf("page_free_list:x\n",page_free_list);
27 // 倒序的?
28 //
29 pages[0].pp_ref = 1;
30 pages[0].pp_link = page_free_list; // null
31 for (i = 1; i < npages_basemem; i++) {
32 pages[i].pp_ref = 0;
33 pages[i].pp_link = page_free_list;
34 page_free_list = &pages[i];
35 }
36 int npages_extmem = EXTPHYSMEM/PGSIZE;
37 int npages_freeextmem = ((uint32_t)(struct PageInfo *)(pages + npages)-KERNBASE)/PGSIZE;
38 for ( int i = npages_freeextmem ; i < npages ; i++)
39 {
40 pages[i].pp_ref = 0 ;
41 pages[i].pp_link = page_free_list;
42 page_free_list = &pages[i];
43 }
44 // debug
45 cprintf("EXTPHYSMEM:x\n",EXTPHYSMEM);
46 cprintf("npages:%d\n",npages);
47 cprintf("npages_IO:%d\n",IOPHYSMEM/PGSIZE);
48 cprintf("npages_extmem:%d npages_freeextmem:%d \n",npages_extmem,npages_freeextmem);
49 cprintf("npages_extmem_VA:x\n",page2kva(&pages[npages_extmem]));
50 }再然后是page_alloc函数。其实就是取一个链表头的操作。
1 struct PageInfo *
2 page_alloc(int alloc_flags)
3 {
4 if (!page_free_list) return NULL;
5 struct PageInfo* ret = page_free_list;
6 page_free_list = page_free_list->pp_link;
7 ret -> pp_link = NULL;
8 memset(page2kva(ret),0,PGSIZE);
9 if (alloc_flags & ALLOC_ZERO)
10 {
11 memset(page2kva(ret),'\0',PGSIZE);
12 }
13 // cprintf("ret:x\n",ret);
14 return ret;
15 }再之后的page_free. 相对应的,就是在链表头插入一个节点的操作。
1
2 void
3 page_free(struct PageInfo *pp)
4 {
5 // Fill this function in
6 // Hint: You may want to panic if pp->pp_ref is nonzero or
7 // pp->pp_link is not NULL.
8 if (pp->pp_ref!=0 || pp->pp_link)
9 {
10 panic("page_free: pp_ref is nonzero or pp_link is not NULL");
11 }
12 // how to return something in a void function?
13 // 相当于在链表头插入一个节点
14 pp->pp_link = page_free_list;
15 page_free_list = pp ;
16 }到现在,练习1就算完成了。怎么知道我们的实现是对的呢,启动JOS,断言应该挂在page_insert处,并且make grade显示Physical page allocator: OK 就应该是没问题了。
Part 2: Virtual Memory#
首先明确一下virtual address,liner address, physical address
简单来说,virtual address就是应用程序使用的地址,包括指针之类的值.
liner address 是virtual address经过segment translation 得到的.
Physical addresses 是 linear addresses 经过paging得到的.
具体来说:
Virtual addresses are used by an application program. They consist of a 16-bit selector and a 32-bit offset. In the flat memory model, the selectors are preloaded into segment registers CS, DS, SS, and ES, which all refer to the same linear address. They need not be considered by the application. Addresses are simply 32-bit near pointers.
Linear addresses are calculated from virtual addresses by segment translation. The base of the segment referred to by the selector is added to the virtual offset, giving a 32-bit linear address.** Under RTTarget-32, virtual offsets are equal to linear addresses since the base of all code and data segments is 0.**
Physical addresses are calculated from linear addresses through paging. The linear address is used as an index into the Page Table where the CPU locates the corresponding physical address. If paging is not enabled, linear addresses are always equal to physical addresses. Under RTTarget-32, linear addresses are equal to physical addresses except for remapped RAM regions
放几张重要的图:
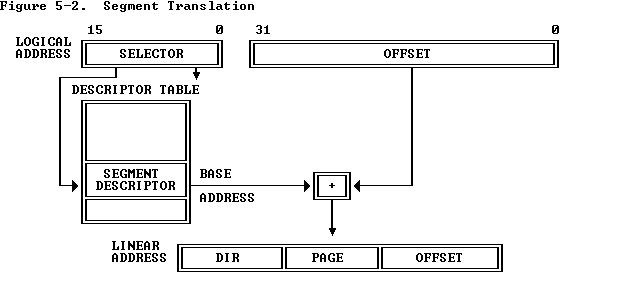

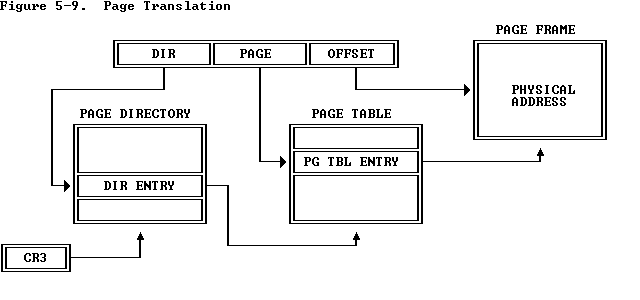
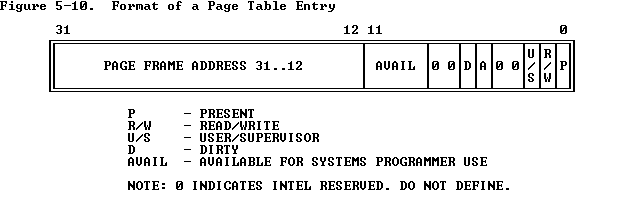
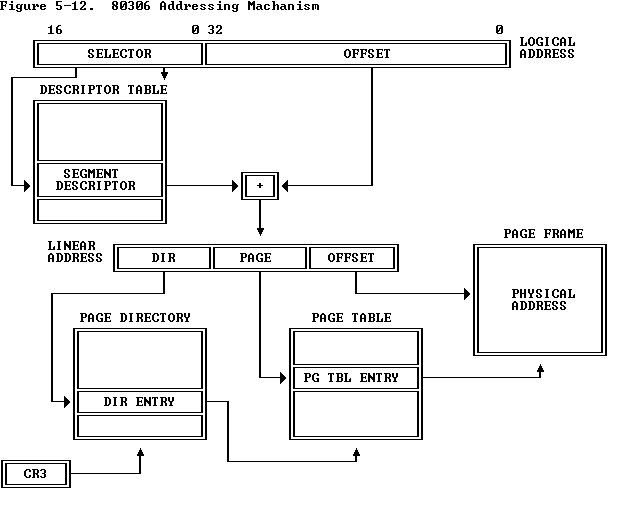
详细情况可以参考Intel 80386 Reference Programmer’s Manual Chapter 5 Memory Management 建议通读,非常短,却又把最重要的内容都讲清楚了.
练习3和question 1都比较水,不说了.
接下来说练习4
ex4 In the file kern/pmap.c, you must implement code for the following functions.
pgdir_walk() boot_map_region() page_lookup() page_remove() page_insert()
check_page(), called frommem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
比较重要的是mmu.h文件,里面有很多有用的宏.
由于要把所有函数都实现完成才能跑通…所以比之前的练习稍微困难了一点…
首先是pgdir_walk函数的实现. 实现的时候有几个地方需要考虑.
第一个是根据注释"The relevant page table page might not exist yet."
那么如何判断一个page是否存在?答案是使用present bit,** (pgdir_entry & PTE_P)为True则表示一个page存在.*
第二个是create一个page的时候,需要两部分. page frame address和各种权限位. page_alloc返回的是PageInfo* ,可以用page2pa得到对应的物理地址.
权限位的设置可以参考6.4 Page-Level Protection 或者下图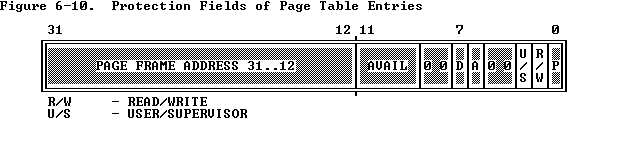
然后第三点,返回的是一个pointer,必须是VA,需要做相应的转换.
1 // Given 'pgdir', a pointer to a page directory, pgdir_walk returns
2 // a pointer to the page table entry (PTE) for linear address 'va'.
3 // This requires walking the two-level page table structure.
4 //
5 // The relevant page table page might not exist yet.
6 // If this is true, and create == false, then pgdir_walk returns NULL.
7 // Otherwise, pgdir_walk allocates a new page table page with page_alloc.
8 // - If the allocation fails, pgdir_walk returns NULL.
9 // - Otherwise, the new page's reference count is incremented,
10 // the page is cleared,
11 // and pgdir_walk returns a pointer into the new page table page.
12 //
13 // Hint 1: you can turn a PageInfo * into the physical address of the
14 // page it refers to with page2pa() from kern/pmap.h.
15 //
16 // Hint 2: the x86 MMU checks permission bits in both the page directory
17 // and the page table, so it's safe to leave permissions in the page
18 // directory more permissive than strictly necessary.
19 //
20 // Hint 3: look at inc/mmu.h for useful macros that manipulate page
21 // table and page directory entries.
22 //
23 pte_t *
24 pgdir_walk(pde_t *pgdir, const void *va, int create)
25 {
26 // Fill this function in
27 //cprintf("*pgdir:x *va:x\n",*pgdir, va);
28 pte_t * pgdir_entry = &pgdir[PDX(va)];
29 bool page_exist = (*pgdir_entry & PTE_P);
30 //cprintf("page_exist %d\n",page_exist);
31 struct PageInfo * pginfo;
32 if (!page_exist)
33 {
34 if (!create) return NULL;
35 else
36 {
37 pginfo = page_alloc(1);
38 //cprintf("pginfo in pgdir_walk:x\n",pginfo);
39 if (!pginfo) return NULL;
40 pginfo->pp_ref++;
41 // 要添加的权限参考 https://pdos.csail.mit.edu/6.828/2018/readings/i386/s06_04.htm
42 *pgdir_entry = (pte_t)page2pa(pginfo) | PTE_U | PTE_W | PTE_P;
43 // return pgdir_entry;
44 }
45 }
46 // what if pre_t present bit is 0?
47 // 注意PTE_ADDR返回的是物理地址,而一个pointer应该指向一个虚拟地址。
48 //
49 pte_t * pgtable_entry = (pte_t *)KADDR(PTE_ADDR(*pgdir_entry))+PTX(va);
50 page_exist = (*pgtable_entry &PTE_P);
51
52 // 提示1有什么作用? 怎么判断page table page是否存在?
53 // 用present bhttps://pdos.csail.mit.edu/6.828/2018/readings/i386/s06_04.htmit 判断?
54 return pgtable_entry;
55 }接下里是boot_map_region. 由于各种参数已经保证了对齐PGSIZE…所以也没什么cornor case.
唯一值得强调的是,map一个VA到PA的含义,其实就是将VA对应的page entry的page frame address设置为PA.
1 //
2 // map一个VA到PA的含义,其实就是将VA对应的page entry的地址设置为PA.
3 // Map [va, va+size) of virtual address space to physical [pa, pa+size)
4 // in the page table rooted at pgdir. Size is a multiple of PGSIZE, and
5 // va and pa are both page-aligned.
6 // Use permission bits perm|PTE_P for the entries.
7 //
8 // This function is only intended to set up the ``static'' mappings
9 // above UTOP. As such, it should *not* change the pp_ref field on the
10 // mapped pages.
11 //
12 // Hint: the TA solution uses pgdir_walk
13 static void
14 boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
15 {
16 // Fill this function in
17 size_t num = size/PGSIZE;
18 for ( size_t i = 0 ; i < num ; i++)
19 {
20 uintptr_t cur_va = va + i*PGSIZE;
21 pte_t * entry = pgdir_walk(pgdir,(const void*)cur_va,1);
22 if (!entry)
23 {
24 panic("pgdir_walk return NULL!");
25 }
26 physaddr_t cur_pa = pa + i*PGSIZE;
27 *entry = cur_pa | perm | PTE_P;
28 }
29 }接下来是page_lookup,作用是从va得到映射到该位置的page的信息.
一开始少判断了一种情况,就是忘记检查返回的*entry,导致一个assert(!page_alloc(0)); 一直过不去…调了蛮久orz
1 // Return the page mapped at virtual address 'va'.
2 // If pte_store is not zero, then we store in it the address
3 // of the pte for this page. This is used by page_remove and
4 // can be used to verify page permissions for syscall arguments,
5 // but should not be used by most callers.
6 //
7 // Return NULL if there is no page mapped at va.
8 //
9 // Hint: the TA solution uses pgdir_walk and pa2page.
10 //
11 struct PageInfo *
12 page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
13 {
14 // Fill this function in
15 pte_t * entry = pgdir_walk( pgdir, va, 0);
16 if (!entry) return NULL;
17 if (pte_store)
18 {
19 *pte_store = entry;
20 }
21 bool exist = *entry & PTE_P;
22 if (!exist) return NULL;
23
24 physaddr_t pa = PTE_ADDR(*entry);
25 cprintf("pa in lookup: x\n",pa);
26 struct PageInfo* ret = pa2page(pa);
27 return ret;
28 }下来是page_remove.
1 // Unmaps the physical page at virtual address 'va'.
2 // If there is no physical page at that address, silently does nothing.
3 //
4 // Details:
5 // - The ref count on the physical page should decrement.
6 // - The physical page should be freed if the refcount reaches 0.
7 // - The pg table entry corresponding to 'va' should be set to 0.
8 // (if such a PTE exists)
9 // - The TLB must be invalidated if you remove an entry from
10 // the page table.
11 //
12 // Hint: The TA solution is implemented using page_lookup,
13 // tlb_invalidate, and page_decref.
14 //
15 void
16 page_remove(pde_t *pgdir, void *va)
17 {
18 // Fill this function in
19 pte_t *entry;
20 struct PageInfo * pginfo = page_lookup(pgdir,va,&entry);
21 //cprintf("VA in page_remove:x\n",va);
22 //cprintf("pginfo in page_remove:x\n",pginfo);
23 if (!pginfo) return;
24 page_decref(pginfo);
25 //pte_t * entry = pgdir_walk(pgdir,va,0);
26 //if (!entry) return;
27 *entry = 0;
28 tlb_invalidate(pgdir,va);
29 //check
30 //entry = pgdir_walk(pgdir,va,0);
31 //cprintf(" va: x entry after page_remove: x\n",va, *entry);
32 }接下来是page_insert.
被坑的一个点是…错误码是带负号的…滑稽
然后我的实现中用了page_lookup…其实不用也完全可以…但是觉得使用page_lookup检查某一个va是否有page存在的逻辑更加合理…
1 // Map the physical page 'pp' at virtual address 'va'.
2 // The permissions (the low 12 bits) of the page table entry
3 // should be set to 'perm|PTE_P'.
4 //
5 // Requirements
6 // - If there is already a page mapped at 'va', it should be page_remove()d.
7 // - If necessary, on demand, a page table should be allocated and inserted
8 // into 'pgdir'.
9 // - pp->pp_ref should be incremented if the insertion succeeds.
10 // - The TLB must be invalidated if a page was formerly present at 'va'.
11 //
12 // Corner-case hint: Make sure to consider what happens when the same
13 // pp is re-inserted at the same virtual address in the same pgdir.
14 // However, try not to distinguish this case in your code, as this
15 // frequently leads to subtle bugs; there's an elegant way to handle
16 // everything in one code path.
17 //
18 //
19 // RETURNS:
20 // 0 on success
21 // -E_NO_MEM, if page table couldn't be allocated
22 //
23 // Hint: The TA solution is implemented using pgdir_walk, page_remove,
24 // and page2pa.
25 //
26
27 int
28 page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
29 {
30 // Fill this function in
31 physaddr_t pa = page2pa(pp);
32 //pte_t *entry = pgdir_walk(pgdir,va,1);
33 pte_t *entry;
34 struct PageInfo * pginfo = page_lookup(pgdir,va,&entry);
35 bool exist = *entry & PTE_P;
36 cprintf("*entry x exist %d pginfo x\n",*entry,exist,pginfo);
37 if (pginfo!=NULL)
38 {
39 if (PTE_ADDR(*entry)== pa)
40 {
41 *entry = pa | perm | PTE_P;
42 return 0;
43 }
44 else
45 {
46 page_remove(pgdir,va);
47 }
48 }
49 entry = pgdir_walk(pgdir,va,1);
50 if (!entry)
51 {
52 return -E_NO_MEM;
53 // 我服了。。错误码还带符号的。。。
54 }
55 *entry = pa | perm | PTE_P;
56 pp->pp_ref++;
57 //cprintf("check_va2pa:x\n",check_va2pa(pgdir,PGSIZE));
58 return 0;
59 }Part 3: Kernel Address Space#
JOS把地址空间整体分为两部分,用户环境和kernel. 这条分界线在ULIM. 具体可以参考memlayout.h中的图.
JOS会把物理地址[0x00000000 ,0x0fffffff] 的256MB空间映射到虚拟空间[0xf0000000 ,0xffffffff ]
做这个地址映射原因之一是"One reason JOS remaps all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address"
1/*
2 * Virtual memory map: Permissions
3 * kernel/user
4 *
5 * 4 Gig --------> +------------------------------+
6 * | | RW/--
7 * ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
8 * : . :
9 * : . :
10 * : . :
11 * |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
12 * | | RW/--
13 * | Remapped Physical Memory | RW/--
14 * | | RW/--
15 * KERNBASE, ----> +------------------------------+ 0xf0000000 --+
16 * KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
17 * | - - - - - - - - - - - - - - -| |
18 * | Invalid Memory (*) | --/-- KSTKGAP |
19 * +------------------------------+ |
20 * | CPU1's Kernel Stack | RW/-- KSTKSIZE |
21 * | - - - - - - - - - - - - - - -| PTSIZE
22 * | Invalid Memory (*) | --/-- KSTKGAP |
23 * +------------------------------+ |
24 * : . : |
25 * : . : |
26 * MMIOLIM ------> +------------------------------+ 0xefc00000 --+
27 * | Memory-mapped I/O | RW/-- PTSIZE
28 * ULIM, MMIOBASE --> +------------------------------+ 0xef800000
29 * | Cur. Page Table (User R-) | R-/R- PTSIZE
30 * UVPT ----> +------------------------------+ 0xef400000
31 * | RO PAGES | R-/R- PTSIZE
32 * UPAGES ----> +------------------------------+ 0xef000000
33 * | RO ENVS | R-/R- PTSIZE
34 * UTOP,UENVS ------> +------------------------------+ 0xeec00000
35 * UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE
36 * +------------------------------+ 0xeebff000
37 * | Empty Memory (*) | --/-- PGSIZE
38 * USTACKTOP ---> +------------------------------+ 0xeeb
39 * | Normal User Stack | RW/RW PGSIZE
40 * +------------------------------+ 0xeebfd000
41 * | |
42 * | |
43 * ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
44 * . .
45 * . .
46 * . .
47 * |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
48 * | Program Data & Heap |
49 * UTEXT --------> +------------------------------+ 0x00800000
50 * PFTEMP -------> | Empty Memory (*) | PTSIZE
51 * | |
52 * UTEMP --------> +------------------------------+ 0x00400000 --+
53 * | Empty Memory (*) | |
54 * | - - - - - - - - - - - - - - -| |
55 * | User STAB Data (optional) | PTSIZE
56 * USTABDATA ----> +------------------------------+ 0x00200000 |
57 * | Empty Memory (*) | |
58 * 0 ------------> +------------------------------+ --+
59 *
60 * (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
61 * "Empty Memory" is normally unmapped, but user programs may map pages
62 * there if desired. JOS user programs map pages temporarily at UTEMP.
63 */接下来看练习5,要求初始化kernel address space.
Ex 5. Fill in the missing code in
mem_init()after the call tocheck_page().Your code should now pass the
check_kern_pgdir()andcheck_page_installed_pgdir()checks.
根据注释实现即可,没有什么难度(虽然因为写错个常数调了半天2333
1boot_map_region(kern_pgdir,UPAGES,sizeof(struct PageInfo)*npages,PADDR(pages),PTE_U|PTE_P);
2boot_map_region(kern_pgdir,KSTACKTOP-KSTKSIZE,KSTKSIZE,PADDR(bootstack),PTE_W|PTE_P);
3//大失误! VA最高是2^32-1,十六进制为0xffffffff,不小心写成了1<<31(2^31)....
4boot_map_region(kern_pgdir,KERNBASE,0xffffffff-KERNBASE,0,PTE_W | PTE_P);// kernel pgdir接下来来填表格,可以部分参考上面的layout图.
2. **What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:**
| Entry | Base Virtual Address | Points to (logically): |
| 1023 | 0xff000000 | Page table for top 4MB of phys memory |
| 1022 | 0xfc000000 | Page table for top * of phys memory |
| . | ? | ? |
| . | ? | ? |
| . | ? | ? |
| 960 | 0xf0000000 | kernel |
| 959 | 0xefc00000 | cpu0's kernel stack(0xefff8000),cpu1's kernel stack(0xeffe8000) |
| 956 | 0xef000000 | npages of PageInfo(0xef000000) |
| 952 | 0xee000000 | bootstack |
| . | ? | ? |
| 2 | 0x00800000 | Program Data & Heap |
| 1 | 0x00400000 | Empty Memory |
| 0 | 0x00000000 | Empty Memory |
接下来回答几个问题:
3.We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
对于JOS来说,主要就是"page-level protection"在起作用. 具体来说,就是PTE_W还有PTE_U两个bit.

4.What is the maximum amount of physical memory that this operating system can support? Why?
最大能支持256MB.因为KERNBASE到4GB之间只有这么大的空间.
如果需要支持更大的物理内存,至少需要先将KERNBASE设置为一个较低的值.
5.How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
让我们来看看我们为了管理内存,我们都做了什么.
首先是一个page dir,大小为一个PGSIZE个字节,也就是4KB
然后是npages个PageInfo,大小为0x40000个字节,也就是256KB
然后是将物理地址的256MB映射到KERNBASE以上的地址,对应于page table [960,1024)共64个page table.每个page table需要PGSIZE个字节,所以一共是64*4096 byte,也就是256KB
6.Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
jmp *x 之后EIP才在KERNBASE地址以上运行. 开了paging却还可以在地地址执行的原因是VA[0,4MB)也被映射到了PA[0,4MB)
这是必要的,原因参见Lab1 “Operating system kernels often like to be linked and run at very high virtual address, such as 0xf0100000, in order to leave the lower part of the processor’s virtual address space for user programs to use.”
那么到现在为止,挑战以外的题目就全部完成了.
Challenge! Extend the JOS kernel monitor with commands to:
- Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter ‘showmappings 0x3000 0x5000’ to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.
- Explicitly set, clear, or change the permissions of any mapping in the current address space.
- Dump the contents of a range of memory given either a virtual or physical address range. Be sure the dump code behaves correctly when the range extends across page boundaries!
- Do anything else that you think might be useful later for debugging the kernel. (There’s a good chance it will be!)
迫于太菜了。。。选了这个可能是最简单的题目。。。实现也很无脑。。。就是模拟
1// Simple command-line kernel monitor useful for
2// controlling the kernel and exploring the system interactively.
3
4#include <inc/stdio.h>
5#include <inc/string.h>
6#include <inc/memlayout.h>
7#include <inc/assert.h>
8#include <inc/x86.h>
9
10#include <kern/console.h>
11#include <kern/monitor.h>
12#include <kern/kdebug.h>
13
14#include <kern/pmap.h> // for challenge 2 in lab2
15#define CMDBUF_SIZE 80 // enough for one VGA text line
16
17
18struct Command {
19 const char *name;
20 const char *desc;
21 // return -1 to force monitor to exit
22 int (*func)(int argc, char** argv, struct Trapframe* tf);
23};
24
25static struct Command commands[] = {
26 { "help", "Display this list of commands", mon_help },
27 { "kerninfo", "Display information about the kernel", mon_kerninfo },
28 {"backtrace","Display infomation about the call stack", mon_backtrace },
29 {"map"," display the physical mappings that apply to a particular range of virtual addresses",mon_showmappings},
30 {"setPTE_P","set the flag of PTE_P",mon_setPTE_P},
31 {"clearPTE_P","clear the flag of PTE_P",mon_clearPTE_P},
32 {"setPTE_W","set the flag of PTE_W",mon_setPTE_W},
33 {"clearPTE_W","clear the flag of PTE_W",mon_clearPTE_W},
34 {"setPTE_U","set the flag of PTE_U",mon_setPTE_U},
35 {"clearPTE_U","clear the flag of PTE_U",mon_clearPTE_U},
36 {"change_flags","change the permission",mon_change_flags},
37 {"mem","dump the contents of a range VA/PA address range ",mon_mem}
38};
39
40/***** Implementations of basic kernel monitor commands *****/
41
42int
43mon_help(int argc, char **argv, struct Trapframe *tf)
44{
45 int i;
46
47 for (i = 0; i < ARRAY_SIZE(commands); i++)
48 cprintf("%s - %s\n", commands[i].name, commands[i].desc);
49 return 0;
50}
51
52int
53mon_kerninfo(int argc, char **argv, struct Trapframe *tf)
54{
55 extern char _start[], entry[], etext[], edata[], end[];
56
57 cprintf("Special kernel symbols:\n");
58 cprintf(" _start x (phys)\n", _start);
59 cprintf(" entry x (virt) x (phys)\n", entry, entry - KERNBASE);
60 cprintf(" etext x (virt) x (phys)\n", etext, etext - KERNBASE);
61 cprintf(" edata x (virt) x (phys)\n", edata, edata - KERNBASE);
62 cprintf(" end x (virt) x (phys)\n", end, end - KERNBASE);
63 cprintf("Kernel executable memory footprint: %dKB\n",
64 ROUNDUP(end - entry, 1024) / 1024);
65 return 0;
66}
67
68int
69mon_backtrace(int argc, char **argv, struct Trapframe *tf)
70{
71 // Your code here.
72 uint32_t *ebp = (uint32_t*)read_ebp();
73 cprintf("Stack backtrace:\n");
74 int i ;
75 struct Eipdebuginfo info;
76 while (ebp)
77 {
78 uint32_t eip = ebp[1];
79 cprintf("ebp x eip x ",ebp,eip);
80 cprintf("args");
81 for ( i = 2 ; i < 7 ; i++)
82 {
83 cprintf(" x",*(ebp+i));
84 }
85 cprintf("\n");
86 int status = debuginfo_eip(eip,&info);
87 if (status == 0)
88 {
89
90 cprintf("%s:%d: ",info.eip_file,info.eip_line);
91 cprintf("%.*s+%d\n",info.eip_fn_namelen,info.eip_fn_name,eip-info.eip_fn_addr);
92 }
93 ebp = (uint32_t*)*ebp;
94 }
95
96
97 return 0;
98}
99
100
101int
102mon_showmappings(int argc, char **argv, struct Trapframe *tf)
103{
104 if (argc<3)
105 {
106 cprintf("USAGE: map [startVA] [endVA] \n");
107 return -1;
108 }
109 char * sstartVA = argv[1];
110 char * sendVA = argv[2];
111 //cprintf("[%s,%s]\n",sstartVA,sendVA);
112 uintptr_t istartVA = strtol(sstartVA,NULL,16);
113 uintptr_t iendVA = strtol(sendVA,NULL,16);
114 //cprintf("int: [x,x]\n",istartVA,iendVA);
115 int cnt = ((iendVA - istartVA)>>12)&0xFFFFFF;
116 //cprintf("cnt %d\n",cnt);
117 cprintf("virtual address phycisal address PTE_U PTE_W PTE_P\n");
118 for ( int i = 0 ; i < cnt ; i++)
119 {
120 uintptr_t curVA = istartVA + i * 0x1000;
121 cprintf(" x ",curVA);
122 pte_t * entry ;
123 struct PageInfo *pginfo = page_lookup(kern_pgdir,(void *)curVA,&entry);
124 if (!pginfo)
125 {
126 cprintf(" None ");
127 cprintf(" None ");
128 cprintf(" None");
129 cprintf(" None\n");
130 }
131 else
132 {
133 physaddr_t pa = PTE_ADDR(*entry);
134 cprintf(" x ",pa);
135 cprintf(" %d %d %d\n",1-!(*entry&PTE_U),1-!(*entry&PTE_W),1-!(*entry&PTE_P));
136 }
137 }
138 return 0;
139}
140
141int
142mon_setPTE_P(int argc, char **argv, struct Trapframe *tf)
143{
144 char *sVA = argv[1];
145 uintptr_t VA = strtol(sVA,NULL,16);
146 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
147 if (!entry)
148 {
149 cprintf("Page table entry not exist!\n");
150 return -1;
151 }
152 *entry = *entry | PTE_P;
153 return 0;
154}
155int
156mon_clearPTE_P(int argc, char **argv, struct Trapframe *tf)
157{
158 char *sVA = argv[1];
159 uintptr_t VA = strtol(sVA,NULL,16);
160 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
161 if (!entry)
162 {
163 cprintf("Page table entry not exist!\n");
164 return -1;
165 }
166 //cprintf("entry x\n",*entry);
167 //cprintf(" PTE_p x\n",(~PTE_P));
168 *entry = (*entry) & (~PTE_P);
169 //cprintf("entry x\n",*entry);
170 return 0;
171}
172
173
174
175int
176mon_setPTE_W (int argc, char **argv, struct Trapframe *tf)
177{
178 char *sVA = argv[1];
179 uintptr_t VA = strtol(sVA,NULL,16);
180 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
181 if (!entry)
182 {
183 cprintf("Page table entry not exist!\n");
184 return -1;
185 }
186 *entry = *entry | PTE_W;
187 return 0;
188
189}
190
191int
192mon_clearPTE_W(int argc, char **argv, struct Trapframe *tf)
193{
194 char *sVA = argv[1];
195 uintptr_t VA = strtol(sVA,NULL,16);
196 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
197 if (!entry)
198 {
199 cprintf("Page table entry not exist!\n");
200 return -1;
201 }
202 *entry = (*entry) & (~PTE_W);
203 return 0;
204
205}
206
207int
208mon_setPTE_U(int argc, char **argv, struct Trapframe *tf)
209{
210 char *sVA = argv[1];
211 uintptr_t VA = strtol(sVA,NULL,16);
212 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
213 if (!entry)
214 {
215 cprintf("Page table entry not exist!\n");
216 return -1;
217 }
218 *entry = *entry | PTE_U;
219 return 0;
220
221}
222int
223mon_clearPTE_U(int argc, char **argv, struct Trapframe *tf)
224{
225 char *sVA = argv[1];
226 uintptr_t VA = strtol(sVA,NULL,16);
227 pte_t * entry = pgdir_walk(kern_pgdir,(void *)VA,0);
228 if (!entry)
229 {
230 cprintf("Page table entry not exist!\n");
231 return -1;
232 }
233 *entry = (*entry ) & (~PTE_U);
234 return 0;
235
236}
237
238int
239mon_change_flags(int argc, char **argv, struct Trapframe *tf)
240{
241 if (argc<3)
242 {
243 cprintf("USAGE: change_flags [VA] [permission] \n");
244 return -1;
245 }
246 char *sVA = argv[1];
247 char *sPer = argv[2];
248 uintptr_t VA = strtol(sVA,NULL,16);
249 int Per = strtol(sPer,NULL,10);
250 //cprintf("Permission:%d\n",Per);
251 pte_t *entry = pgdir_walk(kern_pgdir,(void *)VA,0);
252 if (!entry)
253 {
254 cprintf("Page table entry not exist!\n");
255 return -1;
256 }
257 *entry =( (*entry) & (~0x7) ) | Per;
258 return 0;
259}
260
261
262int
263mon_mem(int argc, char **argv, struct Trapframe *tf)
264{
265 if (argc<4)
266 {
267 cprintf("usage: mem [VA/PA(start)] [VA/PA(end)] P|V \n");
268 return -1;
269 }
270 char *sstartA = argv[1];
271 char *sendA = argv[2];
272 char *type = argv[3];
273 if (type[0]!='P'&&type[0]!='V')
274 {
275 cprintf("usage: mem [VA/PA(start)] [VA/PA(end)] P|V \n");
276 return -1;
277 }
278
279
280 uintptr_t startVA,endVA;
281 if (type[0]=='P')
282 {
283 startVA = strtol(sstartA,NULL,16) + KERNBASE;
284 endVA = strtol(sendA,NULL,16) + KERNBASE;
285 }
286 else
287 {
288 startVA = strtol(sstartA,NULL,16);
289 endVA = strtol(sendA,NULL,16);
290 }
291 startVA = ROUNDUP(startVA,4);
292 endVA = ROUNDUP(endVA,4);
293 int cnt = ((endVA - startVA)>>2);;
294 cprintf("startVA: x endVA:x cnt:%d\n",startVA,endVA,cnt);
295 for ( int i = 0 ; i < cnt ; i++)
296 {
297 void ** cur_VA = (void **)startVA + i;
298 cprintf("[x]:x\n",cur_VA,*cur_VA);
299 }
300
301 return 0;
302
303}
304
305
306/***** Kernel monitor command interpreter *****/
307
308#define WHITESPACE "\t\r\n "
309#define MAXARGS 16
310
311static int
312runcmd(char *buf, struct Trapframe *tf)
313{
314 int argc;
315 char *argv[MAXARGS];
316 int i;
317
318 // Parse the command buffer into whitespace-separated arguments
319 argc = 0;
320 argv[argc] = 0;
321 while (1) {
322 // gobble whitespace
323 while (*buf && strchr(WHITESPACE, *buf))
324 *buf++ = 0;
325 if (*buf == 0)
326 break;
327
328 // save and scan past next arg
329 if (argc == MAXARGS-1) {
330 cprintf("Too many arguments (max %d)\n", MAXARGS);
331 return 0;
332 }
333 argv[argc++] = buf;
334 while (*buf && !strchr(WHITESPACE, *buf))
335 buf++;
336 }
337 argv[argc] = 0;
338
339 // Lookup and invoke the command
340 if (argc == 0)
341 return 0;
342 for (i = 0; i < ARRAY_SIZE(commands); i++) {
343 if (strcmp(argv[0], commands[i].name) == 0)
344 return commands[i].func(argc, argv, tf);
345 }
346 cprintf("Unknown command '%s'\n", argv[0]);
347 return 0;
348}
349
350void
351monitor(struct Trapframe *tf)
352{
353 char *buf;
354
355 cprintf("Welcome to the JOS kernel monitor!\n");
356 cprintf("Type 'help' for a list of commands.\n");
357
358
359 while (1) {
360 buf = readline("K> ");
361 if (buf != NULL)
362 if (runcmd(buf, tf) < 0)
363 break;
364 }
365}We have placed …
详细X
我们已经把内核和用户环境在同一地址空间。为什么将用户程序不能读或写内核的内存?具体机制保护内核内存?