caffe中卷积运算的实现#
暴力实现的卷积大概是这样子的
1
2for w in 1..W
3 for h in 1..H
4 for x in 1..K
5 for y in 1..K
6 for m in 1..M
7 for d in 1..D
8 output(w, h, m) += input(w+x, h+y, d) * filter(m, x, y, d)
9 end
10 end
11 end
12 end
13 end
14end这种方式的效率显然很低,不意外地,caffe中并不是这样实现的.
注释里面说:
Caffe convolves by reduction to matrix multiplication. This achieves high-throughput and generality of input and filter dimensions but comes at the cost of memory for matrices. This makes use of efficiency in BLAS.
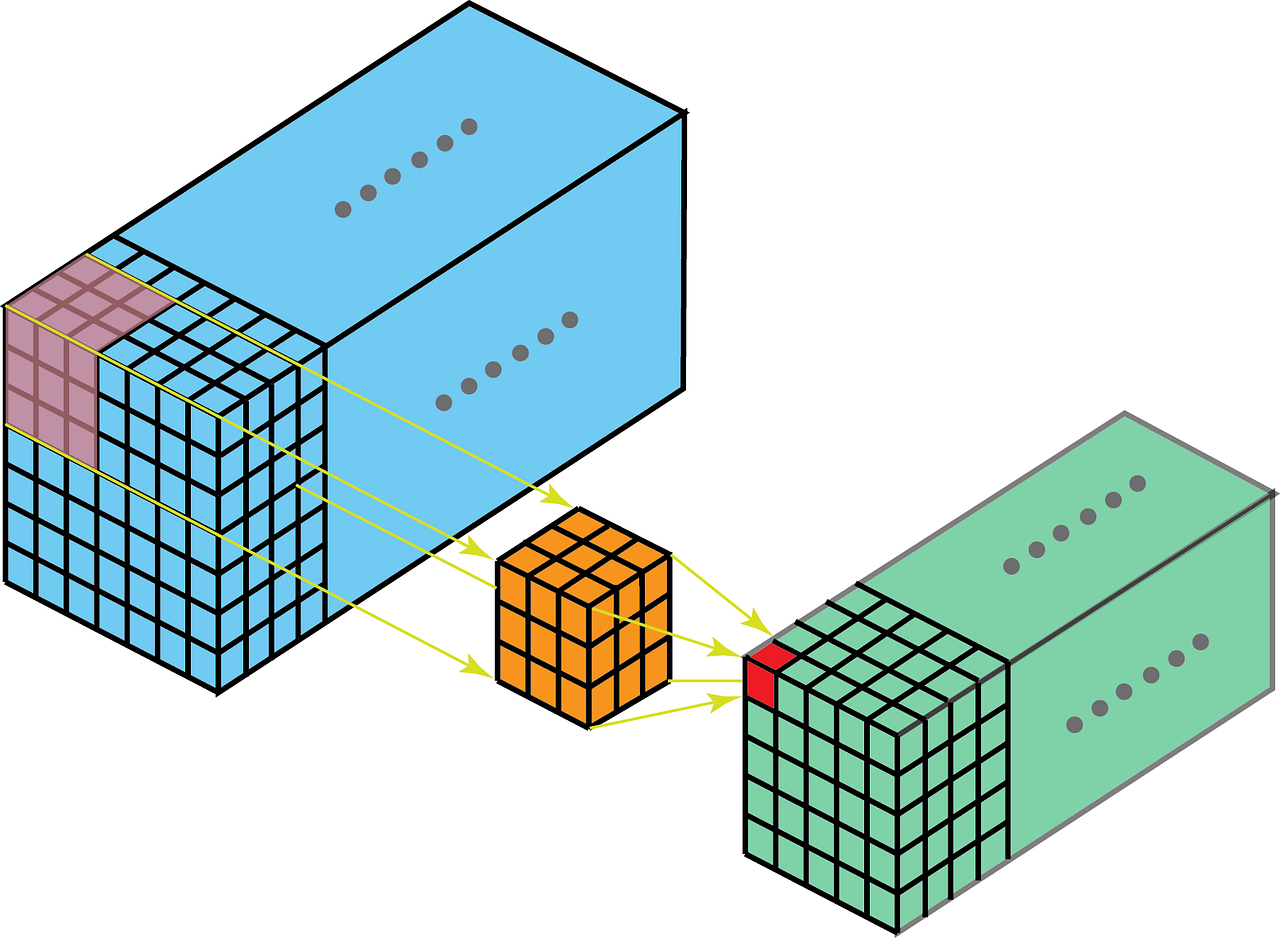
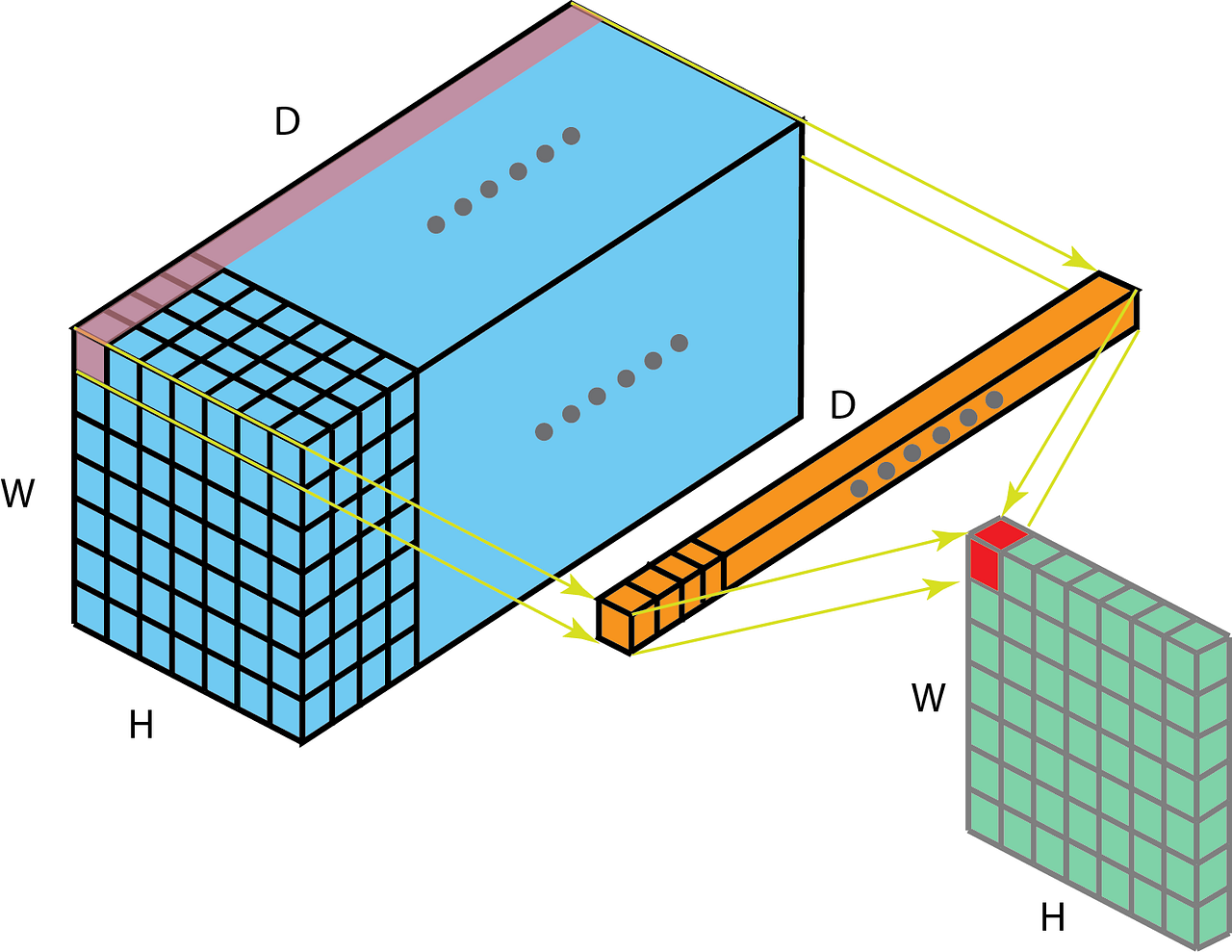
The input is “im2col” transformed to a channel K’ x H x W data matrix for multiplication with the N x K’ x H x W filter matrix to yield a N’ x H x W output matrix that is then “col2im” restored. K’ is the input channel * kernel height * kernel width dimension of the unrolled inputs so that the im2col matrix has a column for each input region to be filtered. col2im restores the output spatial structure by rolling up the output channel N’ columns of the output matrix.
大概意思是说把卷积运算转换成矩阵乘法,然后利用现有的矩阵乘法库来运算.
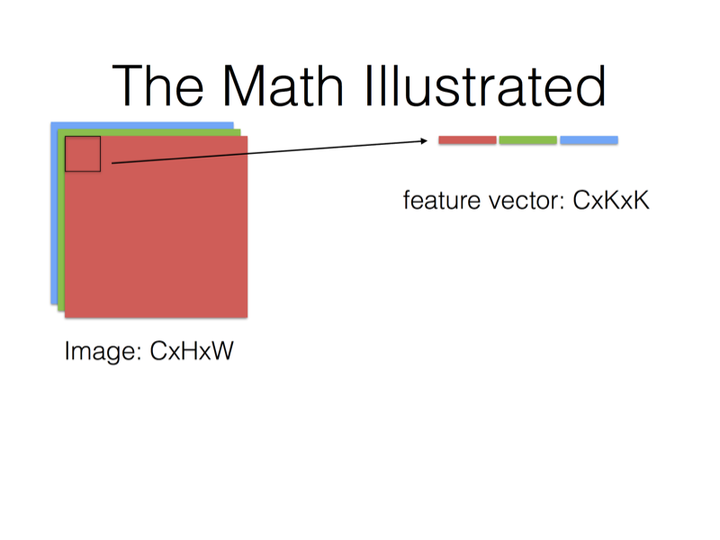
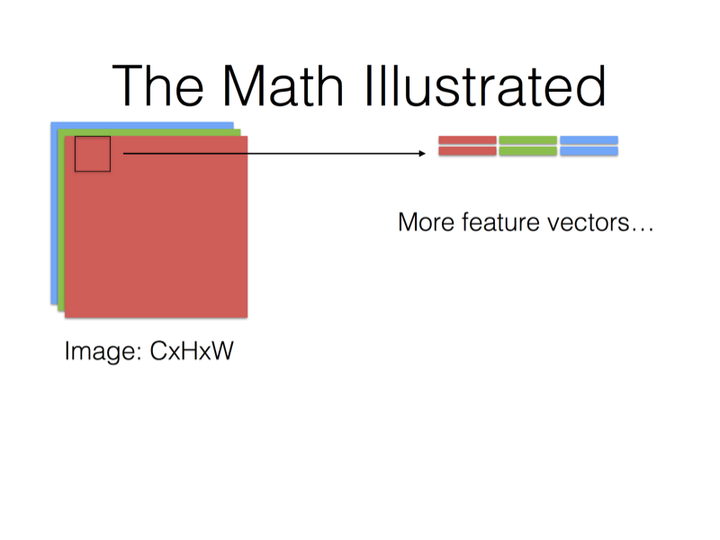
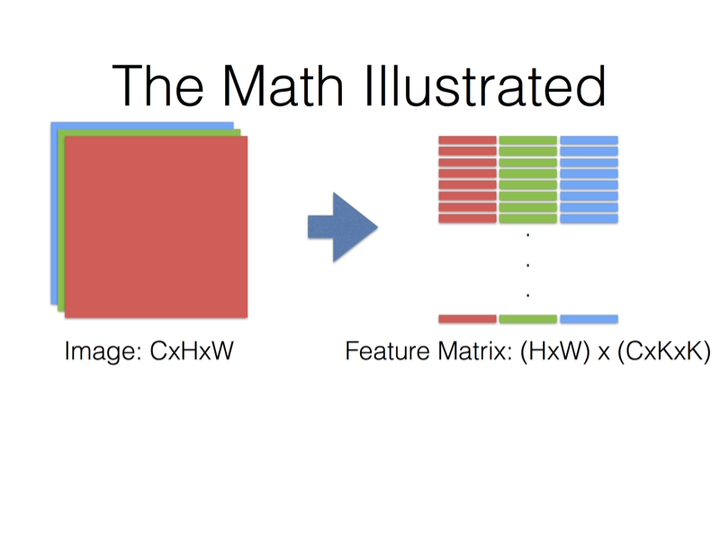
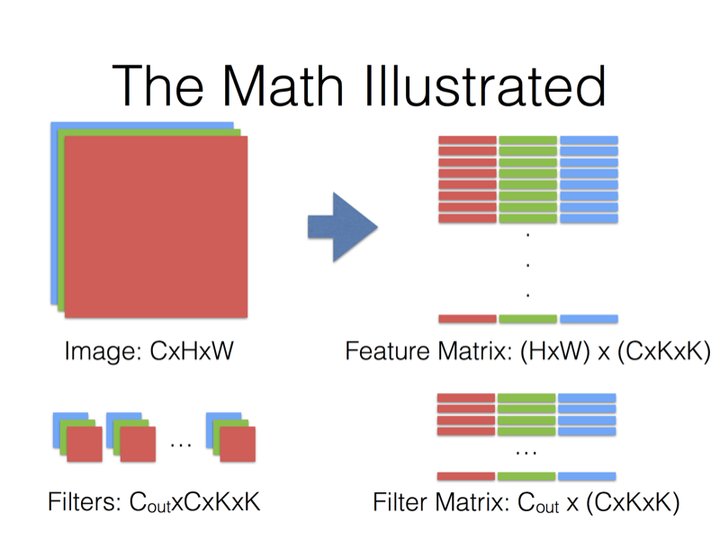
最后就是Filter Matrix乘以Feature Matrix的转置,得到输出矩阵Cout x (H x W)
所以我觉得注释里的filter matrix的尺寸说成是"N*K’“而不是"N x K’ x H x W" 更容易让人理解一些?
需要注意的是,这里为了方便讨论,采用了让输入和输出的feature map的尺寸一致的设置.
caffe代码中src/utill/im2col.cpp 中的 im2col和col2im,都是为了这个优化(指把卷积运算转换成矩阵乘法) 这部分感觉过于detail了,不打算展开.
这里还有caffe作者对这个优化的思考 Convolution in Caffe: a memo
我觉得最值得我们学习的是,不要重复造轮子,先看要解决的问题有没有现成的实现,如果没有,那么能不能把我们要解决的问题转换成有现成实现的问题.
分析完这个运算感觉已经说完了. 我们看一下caffe proto
1
2message ConvolutionParameter {
3 optional uint32 num_output = 1; // The number of outputs for the layer
4 optional bool bias_term = 2 [default = true]; // whether to have bias terms
5
6 // Pad, kernel size, and stride are all given as a single value for equal
7 // dimensions in all spatial dimensions, or once per spatial dimension.
8 repeated uint32 pad = 3; // The padding size; defaults to 0
9 repeated uint32 kernel_size = 4; // The kernel size
10 repeated uint32 stride = 6; // The stride; defaults to 1
11 // Factor used to dilate the kernel, (implicitly) zero-filling the resulting
12 // holes. (Kernel dilation is sometimes referred to by its use in the
13 // algorithme à trous from Holschneider et al. 1987.)
14 repeated uint32 dilation = 18; // The dilation; defaults to 1
15
16 // For 2D convolution only, the *_h and *_w versions may also be used to
17 // specify both spatial dimensions.
18 optional uint32 pad_h = 9 [default = 0]; // The padding height (2D only)
19 optional uint32 pad_w = 10 [default = 0]; // The padding width (2D only)
20 optional uint32 kernel_h = 11; // The kernel height (2D only)
21 optional uint32 kernel_w = 12; // The kernel width (2D only)
22 optional uint32 stride_h = 13; // The stride height (2D only)
23 optional uint32 stride_w = 14; // The stride width (2D only)
24
25 optional uint32 group = 5 [default = 1]; // The group size for group conv
26
27 optional FillerParameter weight_filler = 7; // The filler for the weight
28 optional FillerParameter bias_filler = 8; // The filler for the bias
29 enum Engine {
30 DEFAULT = 0;
31 CAFFE = 1;
32 CUDNN = 2;
33 }
34 optional Engine engine = 15 [default = DEFAULT];
35
36 // The axis to interpret as "channels" when performing convolution.
37 // Preceding dimensions are treated as independent inputs;
38 // succeeding dimensions are treated as "spatial".
39 // With (N, C, H, W) inputs, and axis == 1 (the default), we perform
40 // N independent 2D convolutions, sliding C-channel (or (C/g)-channels, for
41 // groups g>1) filters across the spatial axes (H, W) of the input.
42 // With (N, C, D, H, W) inputs, and axis == 1, we perform
43 // N independent 3D convolutions, sliding (C/g)-channels
44 // filters across the spatial axes (D, H, W) of the input.
45 optional int32 axis = 16 [default = 1];
46
47 // Whether to force use of the general ND convolution, even if a specific
48 // implementation for blobs of the appropriate number of spatial dimensions
49 // is available. (Currently, there is only a 2D-specific convolution
50 // implementation; for input blobs with num_axes != 2, this option is
51 // ignored and the ND implementation will be used.)
52 optional bool force_nd_im2col = 17 [default = false];
53}可以看到,里面有很多参数. 说明caffe是把很多种卷积放在一起实现的. 之后我们逐个分析一下.
各种卷积#
2d卷积#
最最普通的一种
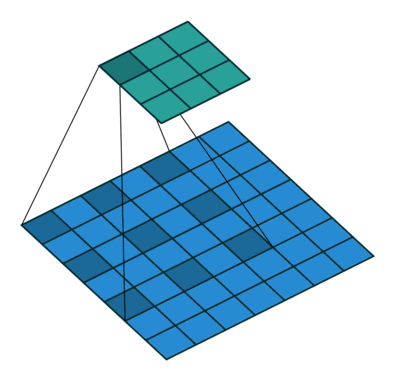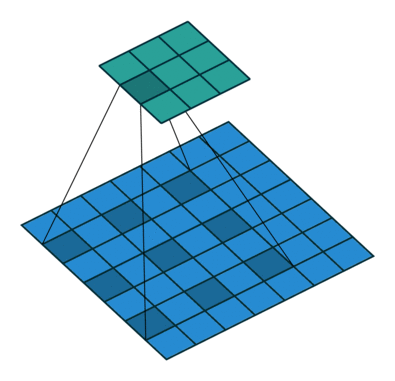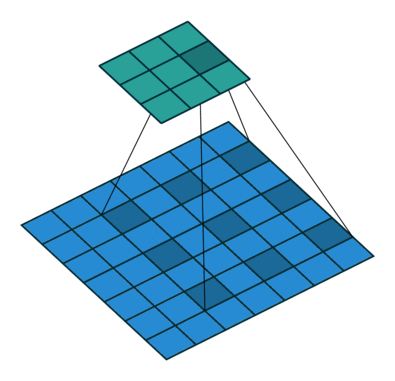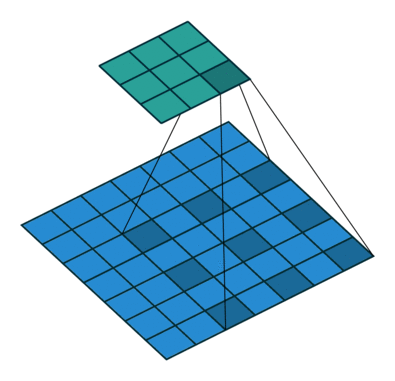
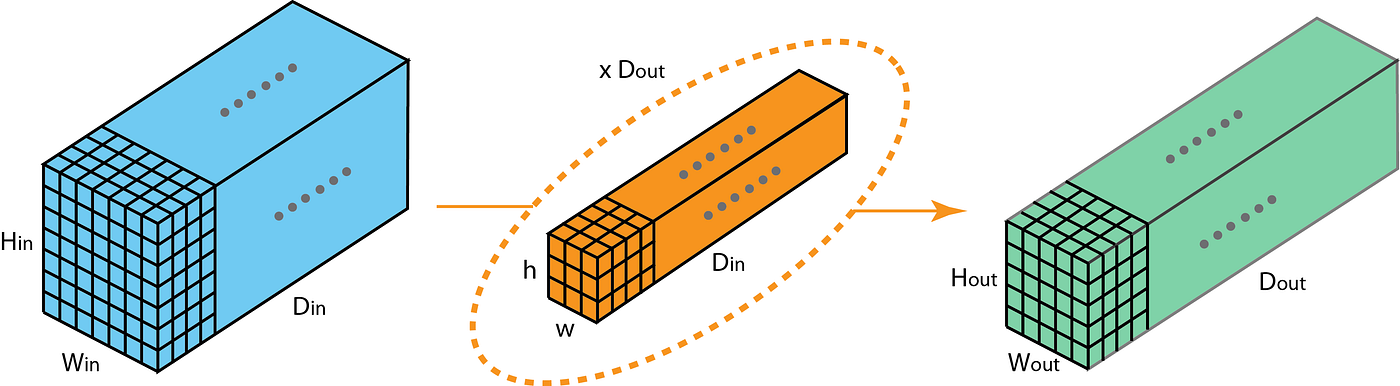
下面的图是一个filter的运算情况.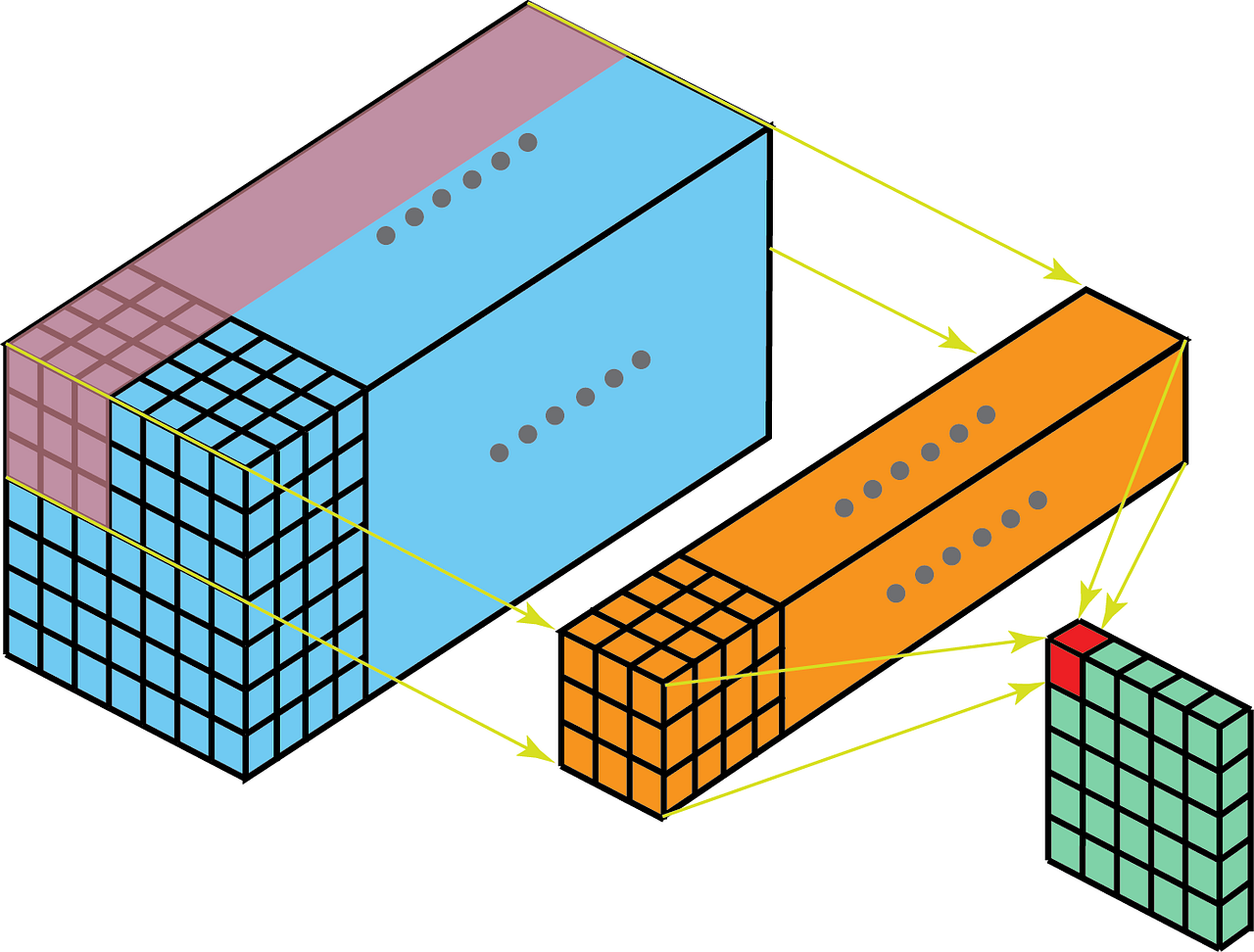
2d可以理解成filter只在height和width两个方向移动
值得一提的是卷积的尺寸计算:
这里关于padding的尺寸还有两个特别有迷惑色彩的词,“valid padding"和"same padding”' 可以参考 What is the difference between ‘SAME’ and ‘VALID’ padding in tf.nn.max_pool of tensorflow?
- valid: 不做任何padding,只在"valid"的区域做卷积.如果filter的一部分超过了feature map的边界,那么就不做卷积.
- same: 并不表示input和output的size相同(只在stride 为1时成立) 而是说如果filter超出了feature map的边界,自动做padding.
3d卷积#
区别主要是 filter 的depth小于 input的depth. 因此在depth方向也可以移动.
1 x 1 卷积#
印象中应该是 Going Deeper with Convolutions中的inception module最先引入了1*1的卷积.
印象错误.. 不过至少算是让这种结构广为人知?
原因是inception module中计算量太大了,因此用1*1的卷积降低维度.
其实1*1的卷积本质上就是对不同channel的feature进行线性组合,只不过这种操作恰好可以通过一种1*1的卷积结构实现.
Transposed Convolution (Deconvolution)#
Transposed Convolution 其实是比较合适的叫法,但是人们也经常用"Deconvolution"来表示.
我们考虑一个 Semantic Segmentation 问题,需要做像素级别的分类.

这样的问题在于计算代价比较大,一般的做法是在encoder阶段抽特征,downsample到一个合适的尺寸,然后在decoder阶段upsample到原图的尺寸.

Transposed Convolution 就是一种做upsample的方式.
正常的卷积是feature map的每个结果是filter和input做点积得到的. Transposed Convolution 是 input表示了filter在feature map上对应位置的权重.
大概长这样:

和这样:

那么这个操作为啥叫"Transposed Convolution"呢 因为这个操作其实是把input feature map的矩阵做了转置,再做正常的卷积.

Dilated Convolution (空洞卷积)#
其中蓝色为输入的feature map,绿色会输出的feature map.
caffe的conv layer是直接支持这种结构的. 似乎是在 Semantic Segmentation 领域比较常见,在工作中没太接触过这种结构.
Spatially Separable Convolutions#
之前完全没有接触过的一种卷积.似乎主要用在移动端设备上使用的网络结构上.主要作用是为了减少卷积的参数量.
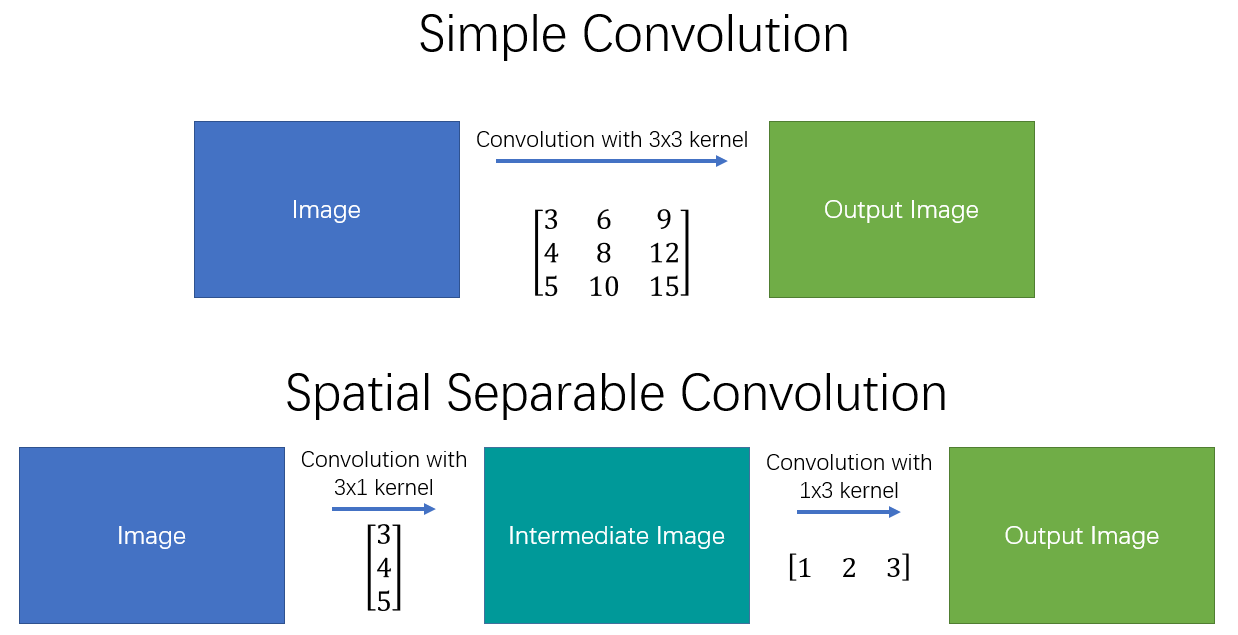
Grouped Convolution#
做鉴黄的同事提了新的需求,于是来看一下这种卷积.
主要作用是通过group conv替代一般的conv,来降低参数量.具体来说,参数为变成原来的1/G. 推倒过程见下图:

截取自 Group Convolution分组卷积,以及Depthwise Convolution和Global Depthwise Convolution (虽然感觉"feature map的数量"叫法怪怪的..感觉一般是把整个depth看做一个feature map? 不过不影响)
主要思想是做卷积时候把N个Filters分成G组,同时把输入的feature map也按照depth分成G组,每组Filters只和对应的feature map做卷积.
先看G=2的情况直观感受一下
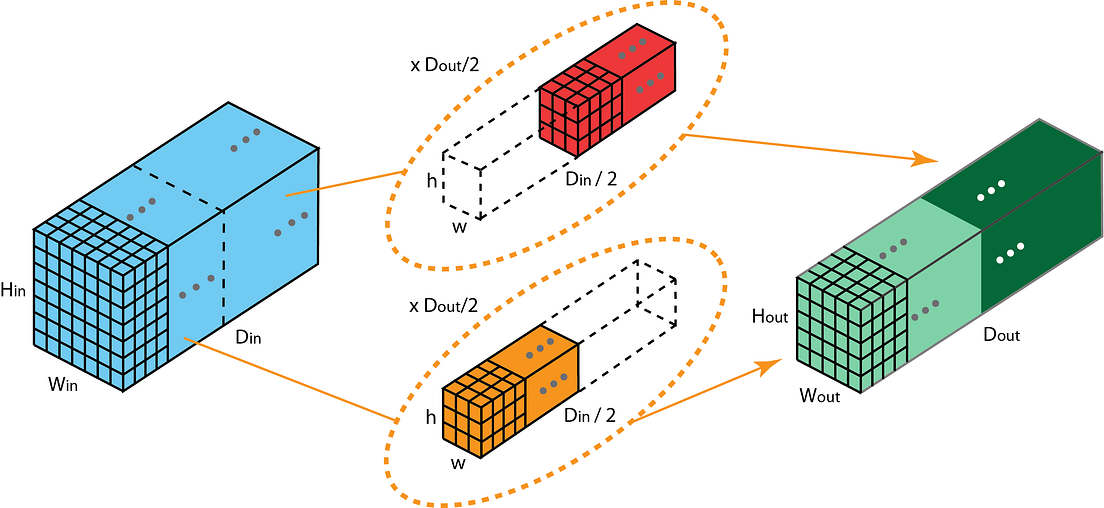
注意图上其实是单个filter的情况,filter的channel变成了一半,只和输入feature map的前一半或者后一半做卷积,然后只会得到一个二维的Wout*Hout的输出feature map. 然后每组的filter的数量也变成了分组前的一半,也就是N/2,加起来还是N.
再来看一个描述全部filter的图,这里G=3
然后简单看一下caffe的实现,主要是看base_conv_layer,是conv_layer的基类. 只挑和group有关的部分.
1
2 group_ = this->layer_param_.convolution_param().group();
3 CHECK_EQ(channels_ % group_, 0);
4 CHECK_EQ(num_output_ % group_, 0)
5 << "Number of output should be multiples of group.";可以看出group数目必须能被filter num和 input feature channels数整除.
1
2
3template <typename Dtype>
4void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
5 const Dtype* weights, Dtype* output, bool skip_im2col) {
6 const Dtype* col_buff = input;
7 if (!is_1x1_) {
8 if (!skip_im2col) {
9 conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
10 }
11 col_buff = col_buffer_.cpu_data();
12 }
13 for (int g = 0; g < group_; ++g) {
14 caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
15 group_, conv_out_spatial_dim_, kernel_dim_,
16 (Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
17 (Dtype)0., output + output_offset_ * g);
18 }
19}实现的也很朴素..就是for循环...group_参数默认为1,为1就是普通的卷积