FilterPolicy接口#
1
2class LEVELDB_EXPORT FilterPolicy {
3 public:
4 virtual ~FilterPolicy();
5
6 // Return the name of this policy. Note that if the filter encoding
7 // changes in an incompatible way, the name returned by this method
8 // must be changed. Otherwise, old incompatible filters may be
9 // passed to methods of this type.
10 virtual const char* Name() const = 0;
11
12 // keys[0,n-1] contains a list of keys (potentially with duplicates)
13 // that are ordered according to the user supplied comparator.
14 // Append a filter that summarizes keys[0,n-1] to *dst.
15 //
16 // Warning: do not change the initial contents of *dst. Instead,
17 // append the newly constructed filter to *dst.
18 virtual void CreateFilter(const Slice* keys, int n,
19 std::string* dst) const = 0;
20
21 // "filter" contains the data appended by a preceding call to
22 // CreateFilter() on this class. This method must return true if
23 // the key was in the list of keys passed to CreateFilter().
24 // This method may return true or false if the key was not on the
25 // list, but it should aim to return false with a high probability.
26 virtual bool KeyMayMatch(const Slice& key, const Slice& filter) const = 0;
27};其中CreateFilter的含义是从n个key生成一个 std::string. 生成的std::string可以包含n个key的信息(类似于生成了一个全集) 从而后续判断某个key是否在其中。
bloomfilter#
一个十分经典的filter 一般用于判断某个元素是否在一个集合中 如果返回false,则一定不存在。 如果返回true,则大概率存在。返回true的情况存在一定的false positive.
基本原理#
其核心原理有两部分:
通过k个hash function对元素进行映射。 类似于从高维空间映射到低维空间。 不同的hash function映射到了不同的低维空间。 如果在每个低维空间,两个元素经过k个hash function的值都相同,那么这两个元素大概率相同。 如果任意一个hash function的值不同,那么这两个element一定不同。
每个元素存k个hash 值还是很占空间,怎么办? 将所有的hash值放到同一个长度为m的bitmap上。 并认为如果一个元素不在集合中,那么大概率至少有一个bit不会被任何全集中的其他元素置为1.
注意,这里说的"经过hash function的值"实际上说的是 “hash(element) % m 的值”,其中m为bitmap的长度
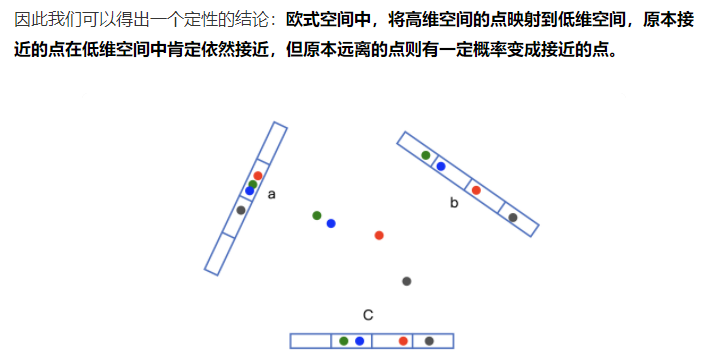
有木有觉得和局部敏感HASH LSH很像? 参考 simdhash笔记 (simhash是用来处理文本相似的LSH算法,后面可以补一个LSH的笔记)
尤其是核心原理中的第一点,几乎是完全一样的。都是利用hash function来做映射从而减少信息。 最大的区别是LSH可以通过hash值的相似度来判断key的相似度,但是bloom filter中用的hash function是非LSH,只能判断相等或者不等。
false positive的来源#
对于不在集合中的元素,有一定概率被误判为在集合中。
这一误判实际上有两方面原因
hash function带来的误判。 可能两个不同的元素的k组 hash(element) % m 得到的值是完全相同的。
将映射之后得到的值放到同一个bitmap上带来的误判。 可能不存在于集合中的元素B算出的k个值恰好被若干个其他元素的结果置为了1. 从而带来误判
bloomfilter在levelDB中的实现#
最佳k值#
有几个值得说明 其一是构造函数中,hash function的个数为 bits_per_key * ln(2)
1
2 explicit BloomFilterPolicy(int bits_per_key) : bits_per_key_(bits_per_key) {
3 // We intentionally round down to reduce probing cost a little bit
4 k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
5 if (k_ < 1) k_ = 1;
6 if (k_ > 30) k_ = 30;
7 }首先要知道,hash function的个数k并不是越多越好。
- 当k太小时,上一节所述的false positive的来源1会更容易发生
- 当k太大时,上一节所述的false positive的来源2会更容易发生(因为每个元素占用了k个bit位,如果k比较大,很容易就把整个bitmap占满了)
那么k的值多少是比较合理的呢? 可以推倒出k最好为 m/n * ln2. 其中m为bitmap的长度,n为key的个数。 m/n就是代码中的bits_per_key

如何得到k个hash function#
k是一个变量,那么问题来了 上哪里找那么多不同的hash function去?
levelDB中采用了double hash的做法来生成k个不同的hash值
而levelDB这里用double hashing生成k个不同的hash value. 计算成本非常低
具体来说,如下代码中的h是hash value1, delta是hash value2(没有用另一个hash function,而是简单的交换前后两部分的bit来生成一个不同的hash value).
1
2 uint32_t h = BloomHash(keys[i]);
3 // kk: 这里每次+delta就相当于生成不同的hash值了
4 // delta是另一个hash value,通过翻转左右两边得到
5 const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
6 // k 是hash函数的个数
7 for (size_t j = 0; j < k_; j++) {
8 // kk: 这里就是把char* 当成bitset 使用
9 const uint32_t bitpos = h % bits;
10 array[bitpos / 8] |= (1 << (bitpos % 8));
11 h += delta;
12 }
13 }bitmap实现#
levledb中没有用std::bitset,而是用一个char数组。每个位置表示8个bit.
另外,最后生成的dst的结构为: 将hash function的个数k encode进了dst中
|bitmap….|k
1 const size_t init_size = dst->size();
2 dst->resize(init_size + bytes, 0);
3 dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
4 // kk: use char array as bitmap
5 // each char has 8 position
6 char* array = &(*dst)[init_size];
7 for (int i = 0; i < n; i++) {
8 // Use double-hashing to generate a sequence of hash values.
9 // See analysis in [Kirsch,Mitzenmacher 2006].
10 uint32_t h = BloomHash(keys[i]);
11 // kk: 这里每次+delta就相当于生成不同的hash值了
12 // delta是另一个hash value,通过翻转左右两边得到
13 const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
14 // k 是hash函数的个数
15 for (size_t j = 0; j < k_; j++) {
16 // kk: 这里就是把char* 当成bitset 使用
17 const uint32_t bitpos = h % bits;
18 array[bitpos / 8] |= (1 << (bitpos % 8));
19 h += delta;
20 }
21 }
22
23
24
25 // Use the encoded k so that we can read filters generated by
26 // bloom filters created using different parameters.
27 const size_t k = array[len - 1];
28 if (k > 30) {
29 // Reserved for potentially new encodings for short bloom filters.
30 // Consider it a match.
31 return true;
32 }
33
34 uint32_t h = BloomHash(key);
35 const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
36 for (size_t j = 0; j < k; j++) {
37 const uint32_t bitpos = h % bits;
38 // 如果其中一个位置为0就返回false
39 if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) return false;
40 h += delta;
41 }
42 return true;一点思考#
通常一个算法是要在空间复杂度和时间复杂度之间做取舍 但是bloom filter的空间和时间复杂度都很优秀,那么牺牲了什么呢? 牺牲了准确率
在一些场景下,的确不需要100%准确。从而对时空复杂度的优化带来了空间。