Home
ACM-ICPC
深度学习
caffe源码阅读笔记
推荐系统
计算机视觉
公开课
6.828
CS341
CSAPP
工程
cpp
cuda
levelDB源码笔记
linux
前端
图像处理
容器
随笔杂谈
面试
About
🌐
中文
English
20160929好虚啊
2016-09-29
· 1 min read
·
算法竞赛
hdu 3967 Zero's Number (不允许前导0(新写法)的数位dp)
2016-09-29
· 2 min read
·
数位dp
FZU 2113 Jason的特殊爱好 (数位dp)
2016-09-28
· 1 min read
·
数位dp
codeforces 145 E. Lucky Queries (线段树lazy标记)
2016-09-27
· 2 min read
·
lazy标记
线段树
codeforces 52 C. Circular RMQ (线段树区间更新,区间询问)
2016-09-25
· 2 min read
·
lazy标记
线段树
重要的事情
2016-09-25
· 1 min read
·
算法竞赛
hdu 5904 LCIS (dp)
2016-09-25
· 1 min read
·
dp
codeforces 455 E. Function (斜率优化,线段树套凸包)
2016-09-25
· 4 min read
·
凸包
斜率优化
线段树
hdu 3507 Print Article (斜率优化dp)
2016-09-24
· 1 min read
·
区间dp
斜率优化
斜率优化学习笔记
2016-09-24
· 1 min read
·
dp
斜率优化
2017 小米 软件工程师 校招 笔试题 (模拟)
2016-09-23
· 1 min read
·
模拟
codeforces 380 C. Sereja and Brackets (线段树区间合并)
2016-09-23
· 2 min read
·
区间合并
线段树
挫败感++
2016-09-22
· 1 min read
·
算法竞赛
【施工中】回文自动机学习笔记
2016-09-22
· 2 min read
·
回文自动机
codeforces 594 D. REQ (树状数组+欧拉函数+逆元)
2016-09-22
· 3 min read
·
number theory
快速幂
树状数组
欧拉函数
逆元
poj 2886 Who Gets the Most Candies? (线段树模拟加强版约瑟夫问题+反素数)
2016-09-21
· 2 min read
·
反素数
线段树
bzoj 1053: [HAOI2007]反素数ant
2016-09-21
· 1 min read
·
number theory
反素数
codeforces 27 E. Number With The Given Amount Of Divisors (dfs,反素数(假))
2016-09-21
· 2 min read
·
dfs
number theory
反素数
hdu 2521 反素数
2016-09-21
· 6 min read
·
number theory
反素数
反素数学习笔记
2016-09-21
· 1 min read
·
number theory
反素数
««
«
24
25
26
27
28
»
»»
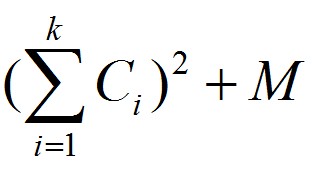 ,求最小代价。
,求最小代价。