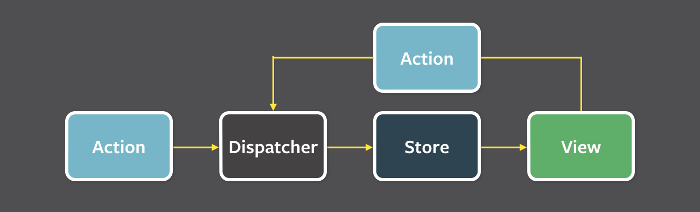
Redux是Flux架构的一种实现。
至于Flux架构是什么,可以参考Flux 架构入门教程
粗略得讲,和MVC架构是同一类东西,最大的区别是单向数据流,禁止了Model和VIEW层之间数据的流动。
阅读更多暂时没空从头开始搞…用到哪里先记录一下好了orz我觉得不行,还是要先大致了解一下。
参考资料:
A re-introduction to JavaScript (JS tutorial)
1// 让我们假设我们有一个对象 o, 其有自己的属性 a 和 b: 2// {a: 1, b: 2} 3// o 的 [[Prototype]] 有属性 b 和 c: 4// {b: 3, c: 4} 5// 最后, o.[[Prototype]].[[Prototype]] 是 null. 6// 这就是原型链的末尾,即 null, 7// 根据定义,null 没有[[Prototype]]. 8// 综上,整个原 …
阅读更多目的是忽略单一对象和组合对象的不同。 有点像以前写过的用链表定义一个树结构,每个节点是一个val + 多个tree 。如果某个节点是叶子节点了,那么对应的tree都为NULL. 只不过这里用了更加面向对象的实现。
阅读更多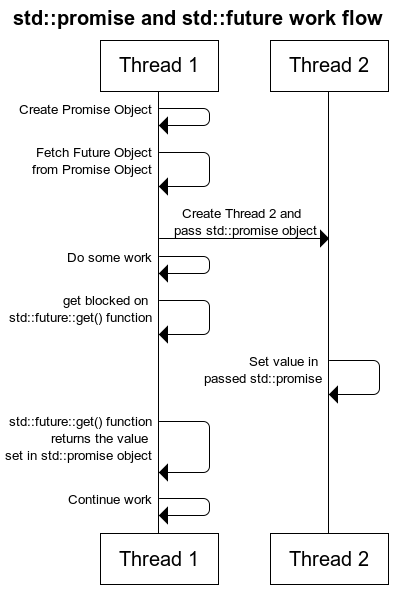
用人话就是,主线程传给附属线程一个promise Object,然后主线程想要获取附属线程set给promise Object的值(也就是该线程返回的某个结果),需要通过主线程中的promise object 得到对应的future object(每个promise 对应一个 future),然后调用future 的get方法。如果附属线程没有执行作为参数传入的promise的set方法去返回结果,那么程序就会block住。
阅读更多1 std::vector<unsigned char> readFromFile1(const char* filePath) { 2 FILE* file = fopen(filePath, "rb"); 3 std::vector<unsigned char> result; 4 if (file == nullptr) { 5 return result; 6 } 7 8 // 获取文件大小,尽量一次读完 9 size_t fileSize = …
阅读更多先放资料:
How to use boost::property_tree to load and write JSON
How to iterate a boost property tree?
不出现key的方法遍历一个json文件:
1 /* *********************************************** 2 Author :111qqz 3 mail: renkuanze@sensetime.com 4 Created Time :2018年08月17日 星期五 15时29分23秒 5 File Name :ptree.cpp 6 …
阅读更多import os
1import math 2ave_err=0.0 3max_err=0.0 4max_err_rate=0.0 5length=0 6with open("cpu_result.txt","r") as fp1, open("cuda_ppl_result.txt","r") as fp2: 7 for l1 in fp1: 8 l2 = fp2.readline() 9 l1=l1[:-2] 10 l2=l2[:-2] 11 lst = l1.split(' …
阅读更多C++11 std::function 是一种通用、多态的函数封装,它的实例可以对任何可 以调用的目标实体进行存储、复制和调用操作
见下面的例子
1 /* *********************************************** 2 Author :111qqz 3 mail: renkuanze@sensetime.com 4 Created Time :2018年07月19日 星期四 17时41分00秒 5 File Name :bind.cpp 6 ************************************************ */ 7 #include …
阅读更多tbb是**Threading Building Blocks library的缩写,**是一个为开发者提供并行解决方案的库.
先放个文档https://www.threadingbuildingblocks.org/intel-tbb-tutorial
阅读更多以前用的办法太老土啦
看到一个since C++11的方法,我觉得比较优雅
1 #include <iostream> 2 #include <chrono> 3 //#include <ratio> 4 #include <thread> 5 6 void f() 7 { 8 std::this_thread::sleep_for(std::chrono::seconds(1)); 9 } 10 11 int main() 12 { 13 auto t1 = std::chrono:: …
阅读更多资料推荐这个:MySQL C API programming tutorial
环境为ubuntu 14.04 lts
需要安装mysql 和mysql 开发包
sudo apt-get install libmysqlclient15-dev mysql-server mysql-client
先在mysql 中建立test数据库和test表格
mysql>create database test; mysql>use test; //切换到test数据库中 mysql> create table test(name varchar(255),num int(10) ); //创 …
阅读更多一个国内vps,一个国外vps.
前提是国外vps已经配置好。
接下来,我们在国内vps上安装haproxy
yum -y install haproxy 或者 apt-get install haproxy
然后修改配置文件,位置在/etc/haproxy/haproxy.cfg
阅读更多20190511更新:
证书到期了,写一下更换证书的流程.
重新申请好证书之后,直接把Apache里面对应的123放到/data/cert文件夹.
其中1对应server-ca.crt,2对应server.crt,3对应server.key
阅读更多迫于拙劣的cpp水平,这次来记录一些关于STL算法部分的内容。
参考内容是CS106L的course reader
Iterator Categories
Iterators分为以下五种:
* Output Iterators:可以使用"++";可以用*myItr = value,不能用value = *myItr * Input Iterators:可以使用"++";可以用value = *myItr,不能用*myItr = value * Forward Iterators: 可以使用"++",可以同时用value = *myItr和*myItr = …
阅读更多迫于拙劣的cpp水平,来补补以前忽略掉的cpp细节。
老规矩,先放资料。
参考资料:
A Gentle Introduction to C++ IO Streams
"Designing and implementing a general input/output facility for a programming language is notoriously difficult" - Bjarne Stroustrup
Stream的基本认识
说说我的理解。stream(流)可以看做输入输出的抽象。我们通过流可以忽略掉device的细节,采取同样的输入输出方式。
阅读更多
Redux是Flux架构的一种实现。
至于Flux架构是什么,可以参考Flux 架构入门教程
粗略得讲,和MVC架构是同一类东西,最大的区别是单向数据流,禁止了Model和VIEW层之间数据的流动。
阅读更多用人话就是,主线程传给附属线程一个promise Object,然后主线程想要获取附属线程set给promise Object的值(也就是该线程返回的某个结果),需要通过主线程中的promise object 得到对应的future object(每个promise 对应一个 future),然后调用future 的get方法。如果附属线程没有执行作为参数传入的promise的set方法去返回结果,那么程序就会block住。
阅读更多